
Recovering pixel-wise geometric properties from a single image is fundamentally ill-posed due to appearance ambiguity and non-injective mappings between 2D observations and 3D structures. While discriminative regression models achieve strong performance through large-scale supervision, their success is bounded by the scale, quality and diversity of available data and limited physical reasoning. Recent diffusion models exhibit powerful world priors that encode geometry and semantics learned from massive image-text data, yet directly reusing their stochastic generative formulation is suboptimal for deterministic geometric inference: the former is optimized for diverse and high-fidelity image generation, whereas the latter requires stable and accurate predictions.
In this work, we propose Lotus-2, a two-stage deterministic framework for stable, accurate and fine-grained geometric dense prediction, aiming to provide an optimal adaption protocol to fully exploit the pre-trained generative priors.
Specifically, in the first stage, the core predictor employs a single-step deterministic formulation with a clean-data objective and a lightweight local continuity module (LCM) to generate globally coherent structures without grid artifacts. In the second stage, the detail sharpener performs a constrained multi-step rectified-flow refinement within the manifold defined by the core predictor, enhancing fine-grained geometry through noise-free deterministic flow matching.
Using only 59K training samples—less than 1% of existing large-scale datasets—Lotus-2 establishes new state-of-the-art results in monocular depth estimation and highly competitive surface normal prediction. These results demonstrate that diffusion models can serve as deterministic world priors, enabling high-quality geometric reasoning beyond traditional discriminative and generative paradigms.
We argue that directly inheriting the stochastic generative formulation—which is optimized for image synthesis—introduces instability and unnecessary complexity for deterministic geometric tasks. The image synthesis aims at diverse and high-fidelity generation through stochastic multi-step sampling, while the dense prediction requires a deterministic and accurate inference. This fundamental misalignment results in high structural variance and significant prediction errors for dense prediction, thereby compromising overall accuracy. To better exploit the generative world priors, we propose a decoupled, two-stage adaption protocol.
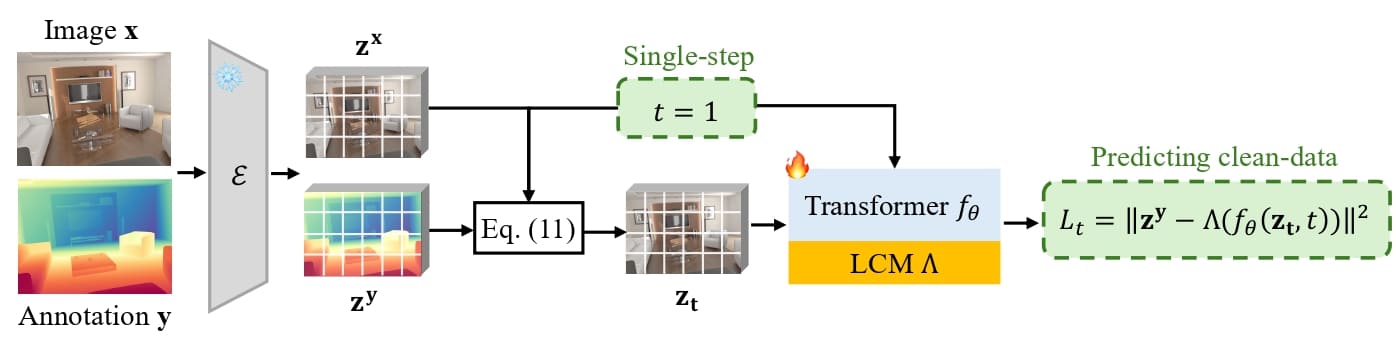
Adaptation protocol of the core predictor in Lotus-2. It adopts a single-step formulation ($t=1$) with clean-data prediction to efficiently exploit the world priors of pre-trained FLUX model, where input latent $\mathbf{z_t}$ is equivalent to the image latent $\mathbf{z^x}$, i.e, $\mathbf{z_t}=\mathbf{z_1}=\mathbf{z^x}$ according to the Eq. 11. In addition, there is a pair of Pack-Unpack operations around the diffusion Transformer $f_\theta$ inherited from FLUX, a local continuity module (LCM) $\Lambda$ is employed to mitigate grid artifacts caused by this Unpack operation.
In the first stage, a core predictor extracts globally coherent and accurate geometry through a simple yet effective adaptation of the rectified-flow formulation in FLUX. By systematically analyzing the key designs of stochastic generative formulation, including the stochasticity, multi-step sampling and parameterization type, we identify that a single-step deterministic formulation under a clean-data prediction yields much better stable and accurate results than the original stochastic multi-step residual-based design. This single-step predictor is further enhanced with a lightweight local continuity module (LCM), which mitigates grid artifacts introduced by the non-parametric Pack-Unpack operations in FLUX while maintaining architectural compatibility and efficiency.
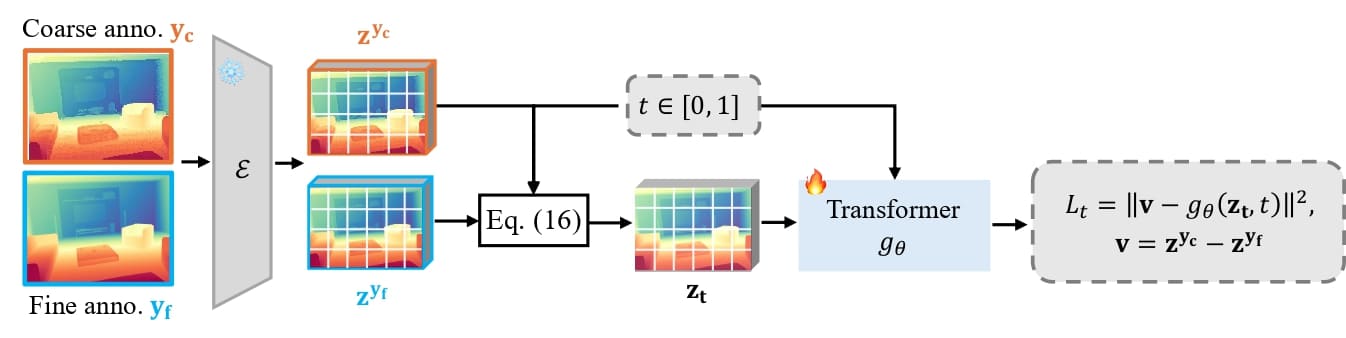
The training pipeline of detail sharpener. Starting from a structurally correct but coarse annotation predicted by the core predictor, the detail sharpener learns the transition from coarse to fine-grained annotation via a constrained multi-step rectified-flow within the manifold defined by the core predictor.
In the second stage, an optional detail sharpener performs a detail refinement through a deterministic multi-step rectified-flow process. It operates within the constrained manifold defined by the core predictor and learns the transition from the "accurate" to "accurate and fine-grained" annotation, progressively enriching geometric details while preserving global structure and accuracy. This design bridges the gap between regression and generative modeling: the former ensures structural stability and correctness, while the latter contributes fine-grained realism. Consequently, Lotus-2 effectively leverages the generative priors in a disciplined and interpretable manner, achieving both geometric consistency and high-frequency detail fidelity without sacrificing efficiency and stability.

The inference pipeline of Lotus-2. It is a decoupled, two-stage deterministic pipeline that bridges the regression and geometric refinement. First, the core predictor produces stable and structurally consistent prediction via single-step regression. The detail sharpener then employs a constrained multi-step rectified-flow formulation to iteratively refinement without any stochastic noise. The refinement uses $T_{\text{inf}}' \leq 10$ steps, adjustable based on the desired level of sharpness. This design ensures both structural consistency and fine-grained fidelity in minimal steps.
The complete inference process proceeds as follows:
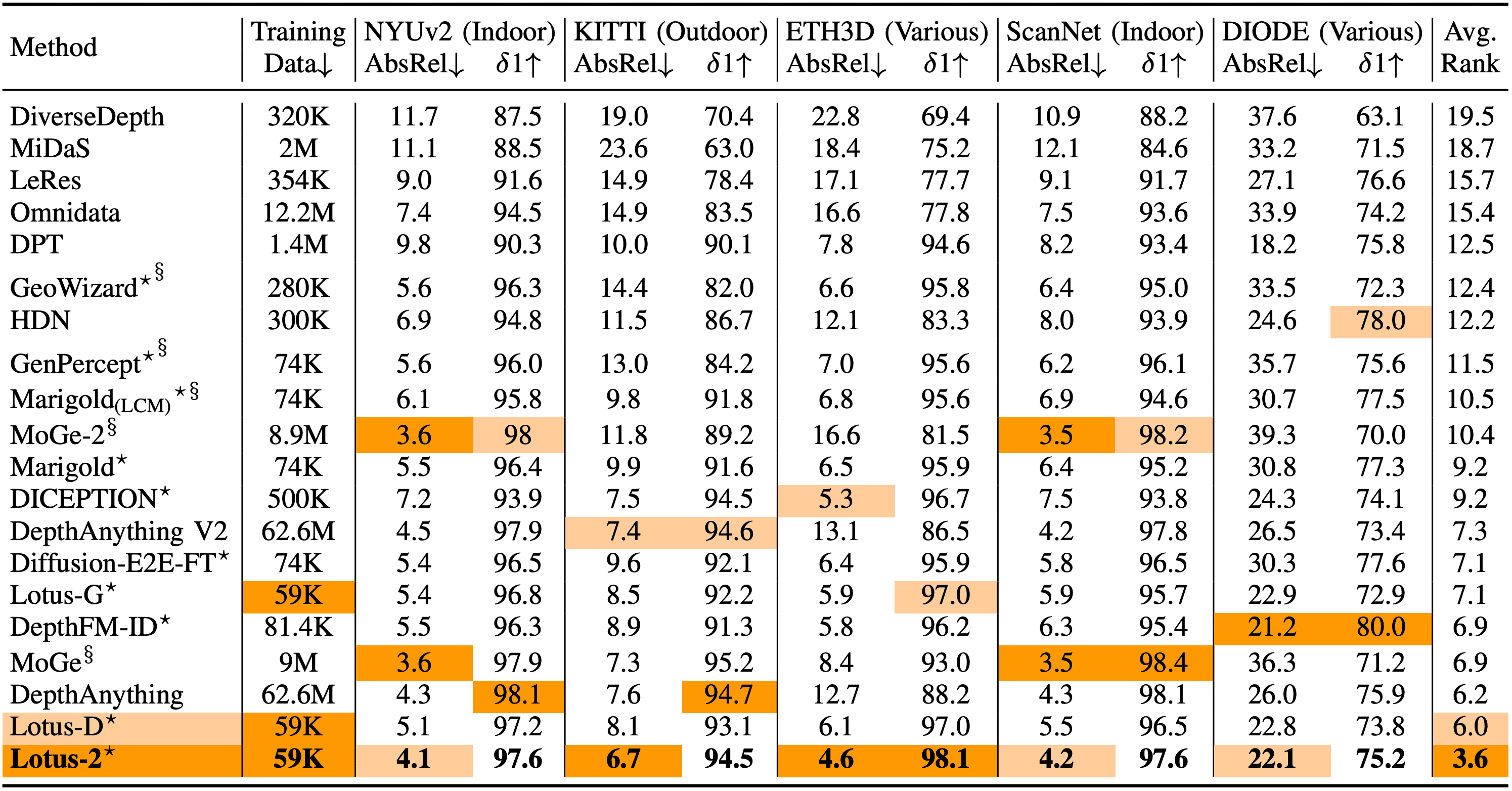
Quantitative comparison on zero-shot affine-invariant depth estimation between Lotus-2 and SoTA methods. The best and second best performances are highlighted. $^\S$indicates results re-evaluated by ourselves using the evaluation protocol of Marigold. $^\star$denotes the method relies on pre-trained text-to-image generative models. Ours Lotus-2 achieves the best overall performance than all other methods.
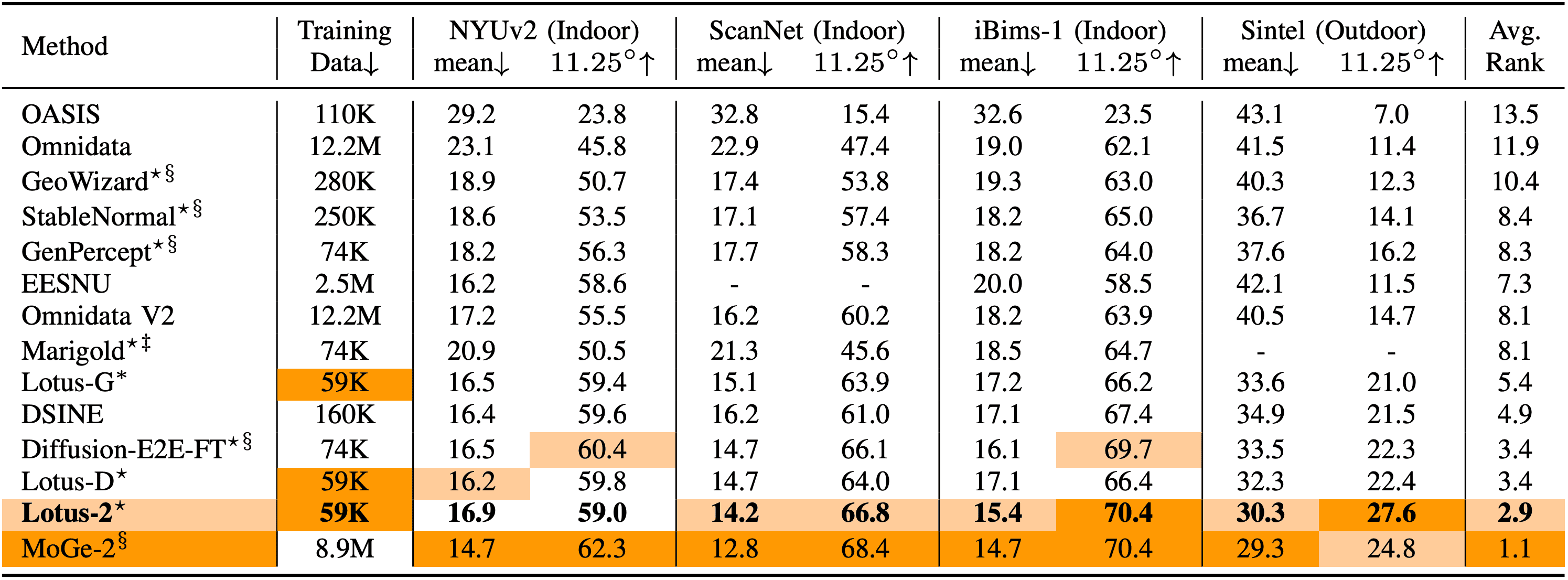
Quantitative comparison on zero-shot surface normal estimation between Lotus-2 and SoTA methods. ‡ refers the Marigold normal model as detailed in this link. $^\S$indicates results re-evaluated by us using the evaluation protocol of DSINE. Our Lotus-2 demonstrates highly competitive quantitative performance, crucially delivering the robust and fine-grained qualitative results as highlighted in Fig. 1.
@article{he2025lotus,
title={Lotus-2: Advancing Geometric Dense Prediction with Powerful Image Generative Model},
author={He, Jing and Li, Haodong and Sheng, Mingzhi and Chen, Ying-Cong},
journal={arXiv preprint arXiv:2512.01030},
year={2025}
}